Res-Tuning: A Flexible and Efficient Tuning Paradigm via Unbinding Tuner from Backbone
Zeyinzi Jiang 1 Chaojie Mao 1 Ziyuan Huang 2 Ao Ma 1 Yiliang Lv 1 Yujun Shen 3 Deli Zhao 1 Jingren Zhou 1
1 Alibaba Group 2 National University of Singapore 3 Ant Group
Abstract
Parameter-efficient tuning has become a trend in transferring large-scale foundation models to downstream applications. Existing methods typically embed some light-weight tuners into the backbone, where both the design and the learning of the tuners are highly dependent on the base model. This work offers a new tuning paradigm, dubbed Res-Tuning, which intentionally unbinds tuners from the backbone. With both theoretical and empirical evidence, we show that popular tuning approaches have their equivalent counterparts under our unbinding formulation, and hence can be integrated into our framework effortlessly. Thanks to the structural disentanglement, we manage to free the design of tuners from the network architecture, facilitating flexible combination of various tuning strategies. We further propose a memory-efficient variant of Res-Tuning, where the bypass (i.e., formed by a sequence of tuners) is effectively detached from the main branch, such that the gradients are back-propagated only to the tuners but not to the backbone. Such a detachment also allows one-time backbone forward for multi-task inference. Extensive experiments on both discriminative and generative tasks demonstrate the superiority of our method over existing alternatives from the perspectives of efficacy and efficiency.
Features
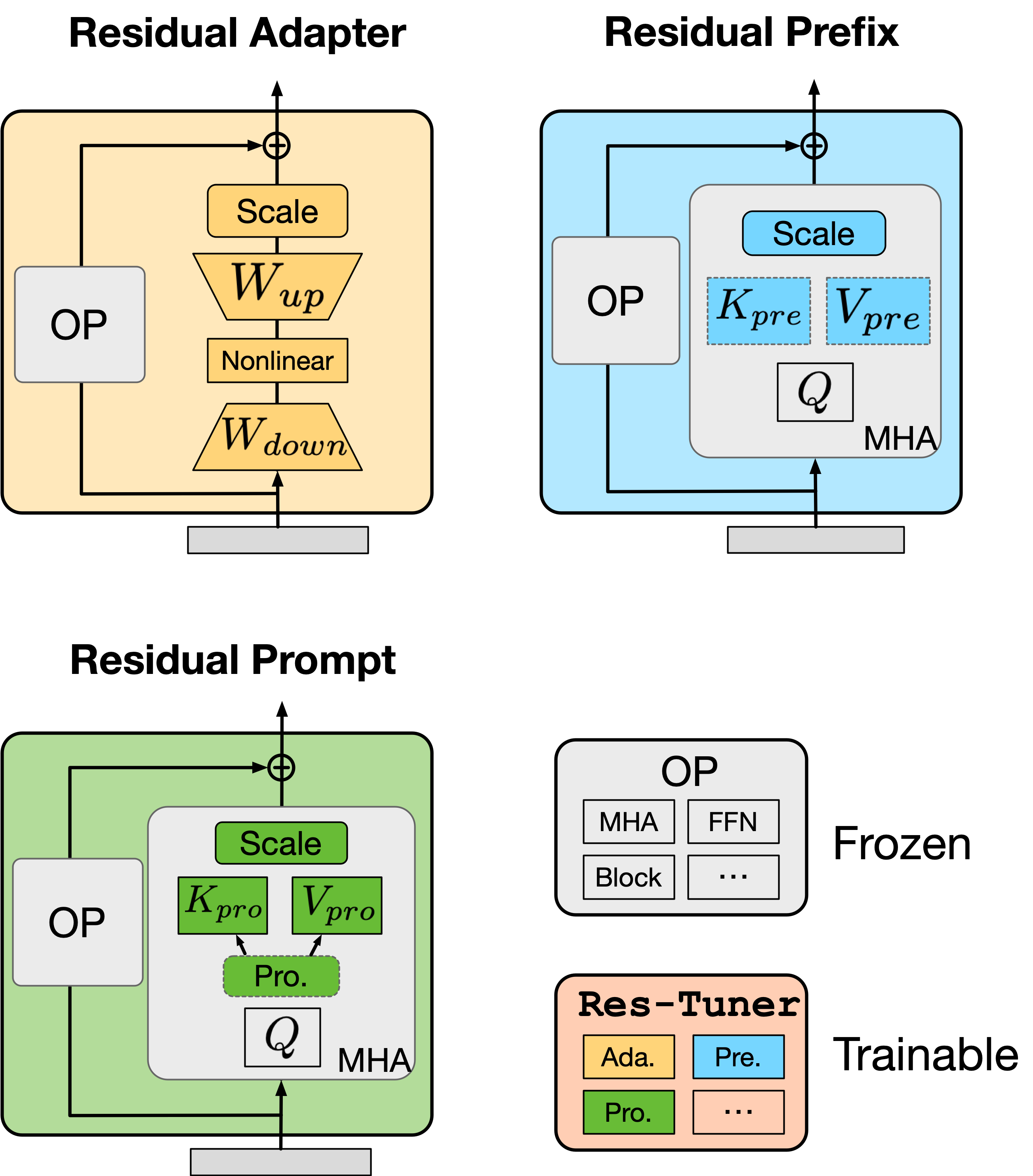
Res-Tuner : unbinds tuners from backbone
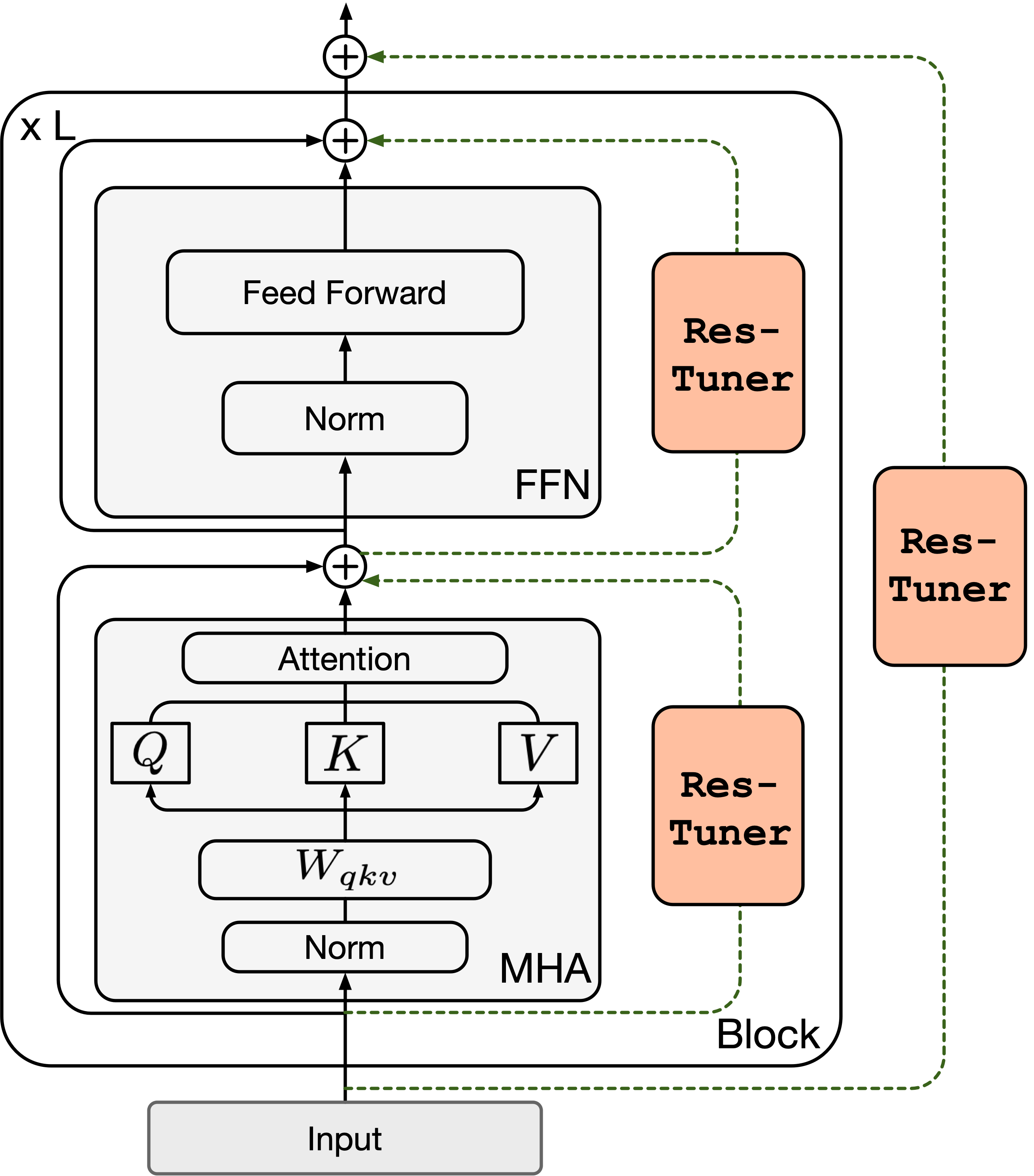
Res-Tuning : unified formulation
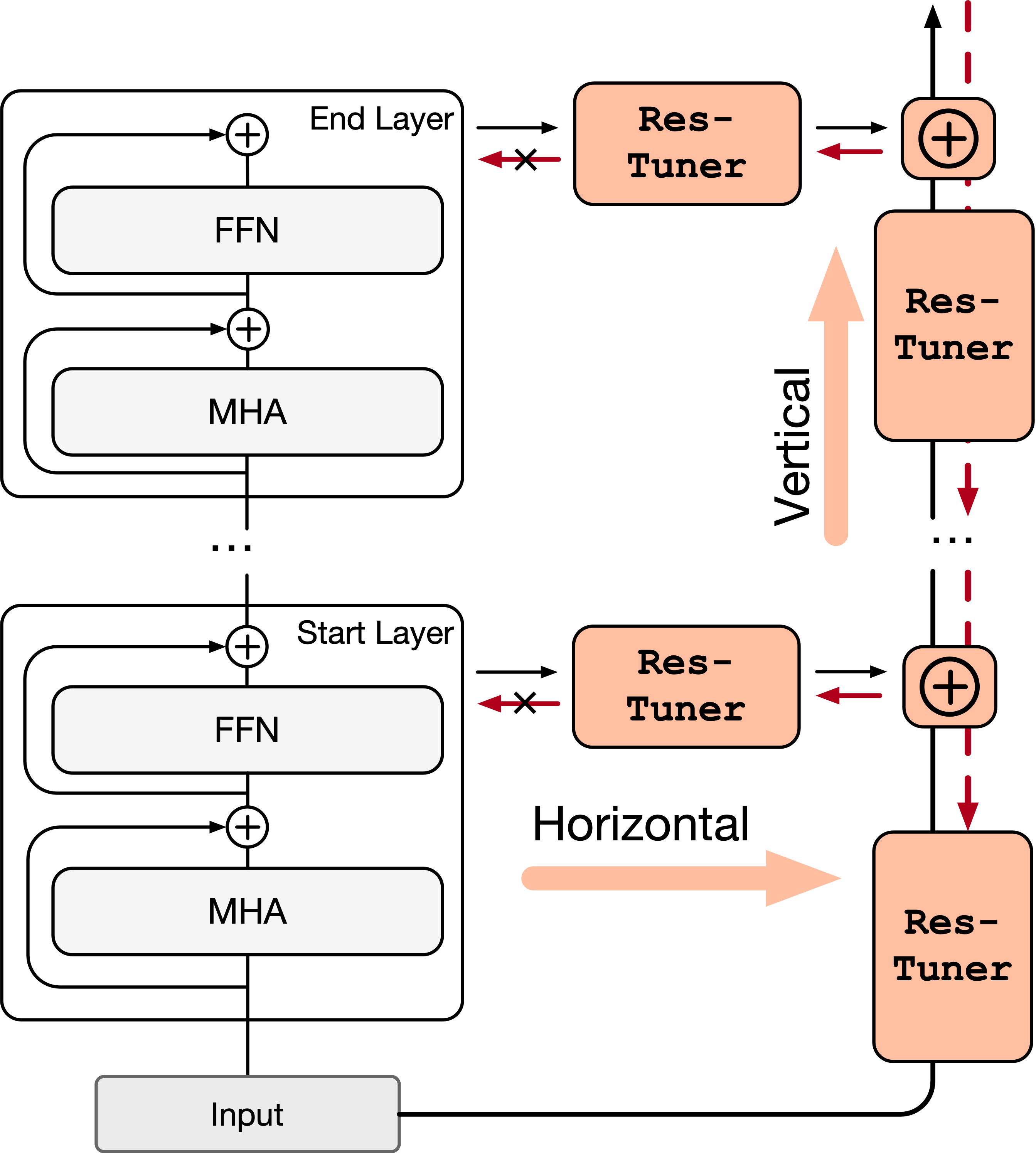
Res-Tuning-Bypass : backpropagation only on Bypass
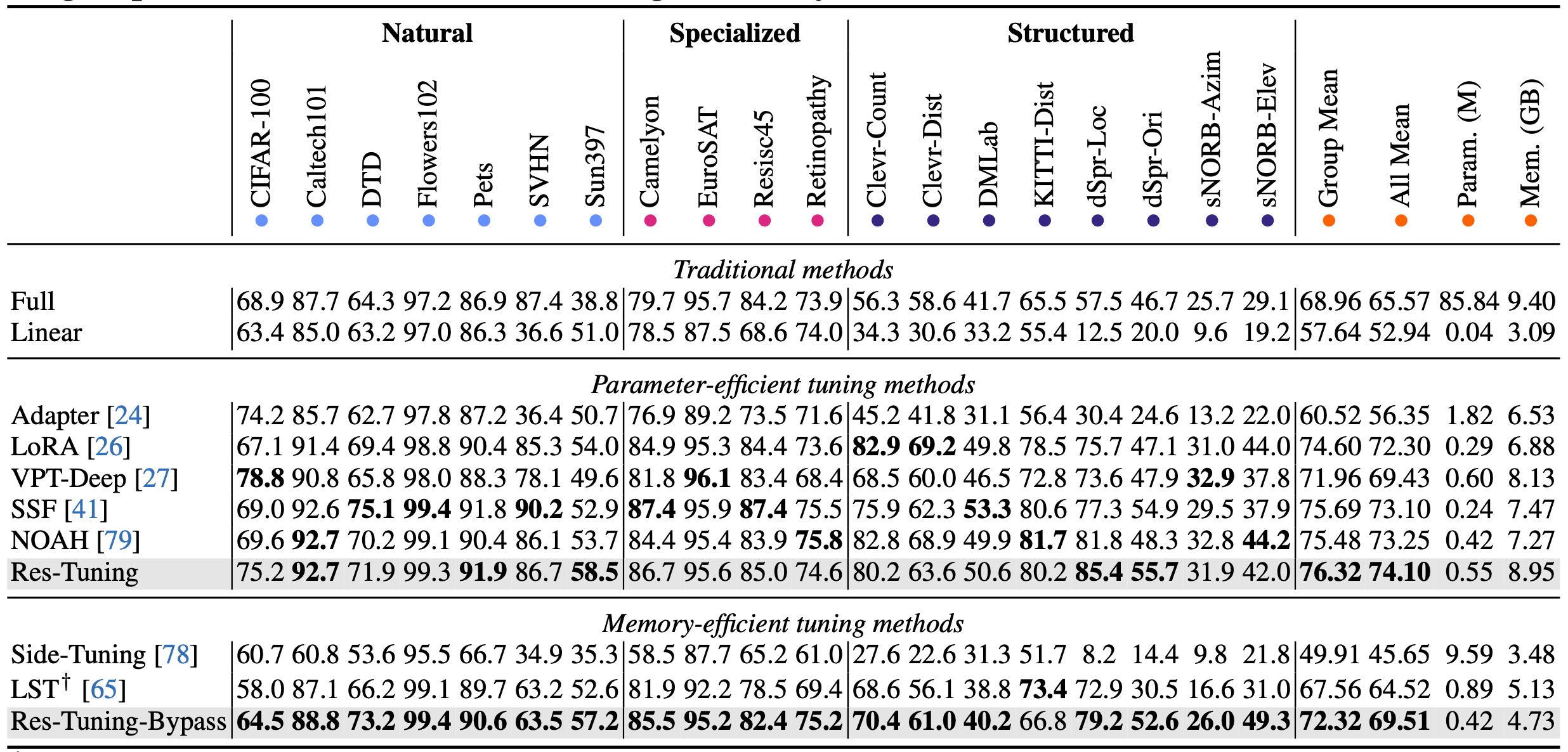
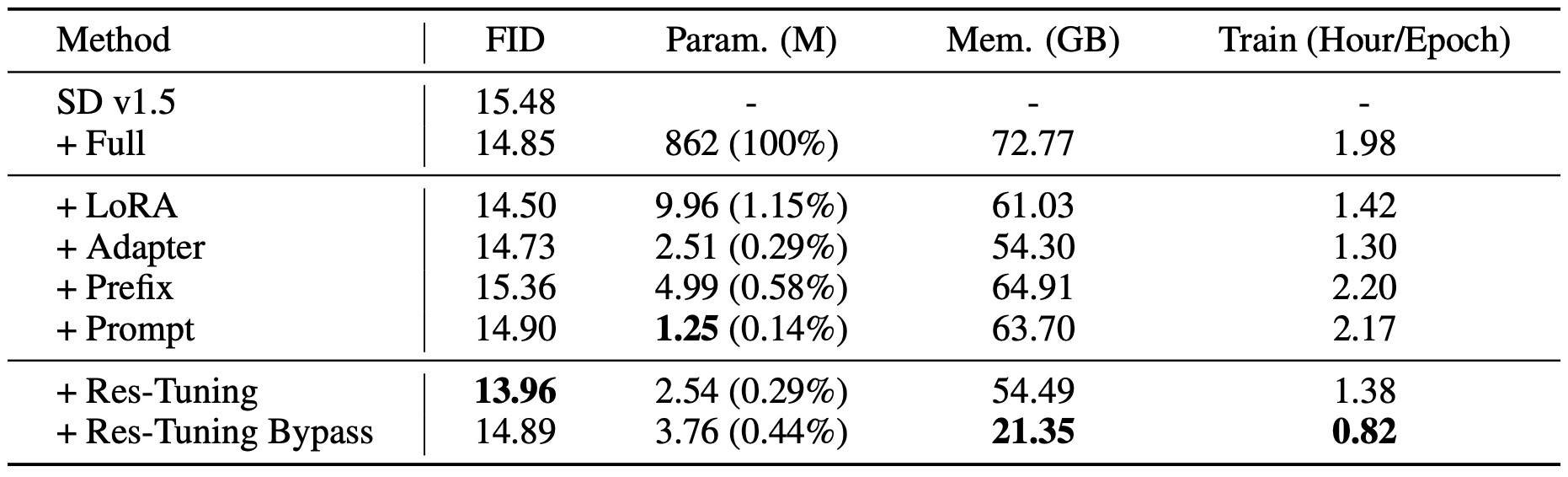
Quantitative Results
Qualitative Results


More Visualizations












Concat
If you're looking for an exciting challenge and the opportunity to work with cutting-edge technologies in AIGC and foundation model, then we are the place for you. We are looking for talented, motivated and creative individuals to join our team. If you are interested, please send your CV to chaojie.mcj@alibaba-inc.com
Citation
@inproceedings{jiang2023restuning,
title={Res-Tuning: A Flexible and Efficient Tuning Paradigm via Unbinding Tuner from Backbone},
author={Jiang, Zeyinzi and Mao, Chaojie and Huang, Ziyuan and Ma, Ao and Lv, Yiliang and Shen, Yujun and Zhao, Deli and Zhou, Jingren},
booktitle={Advances in Neural Information Processing Systems},
year={2023}
}